
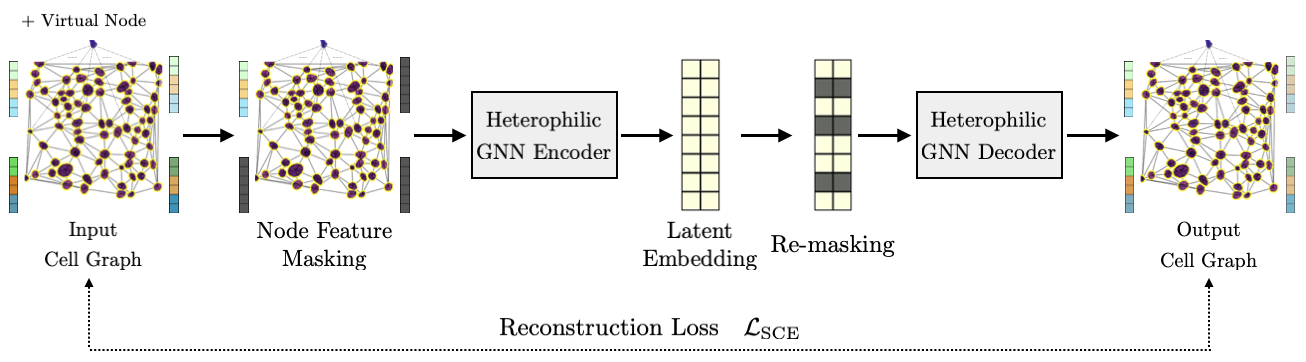
This paper proposes GrapHist, a large-scale graph self-supervised learning framework for histopathology.
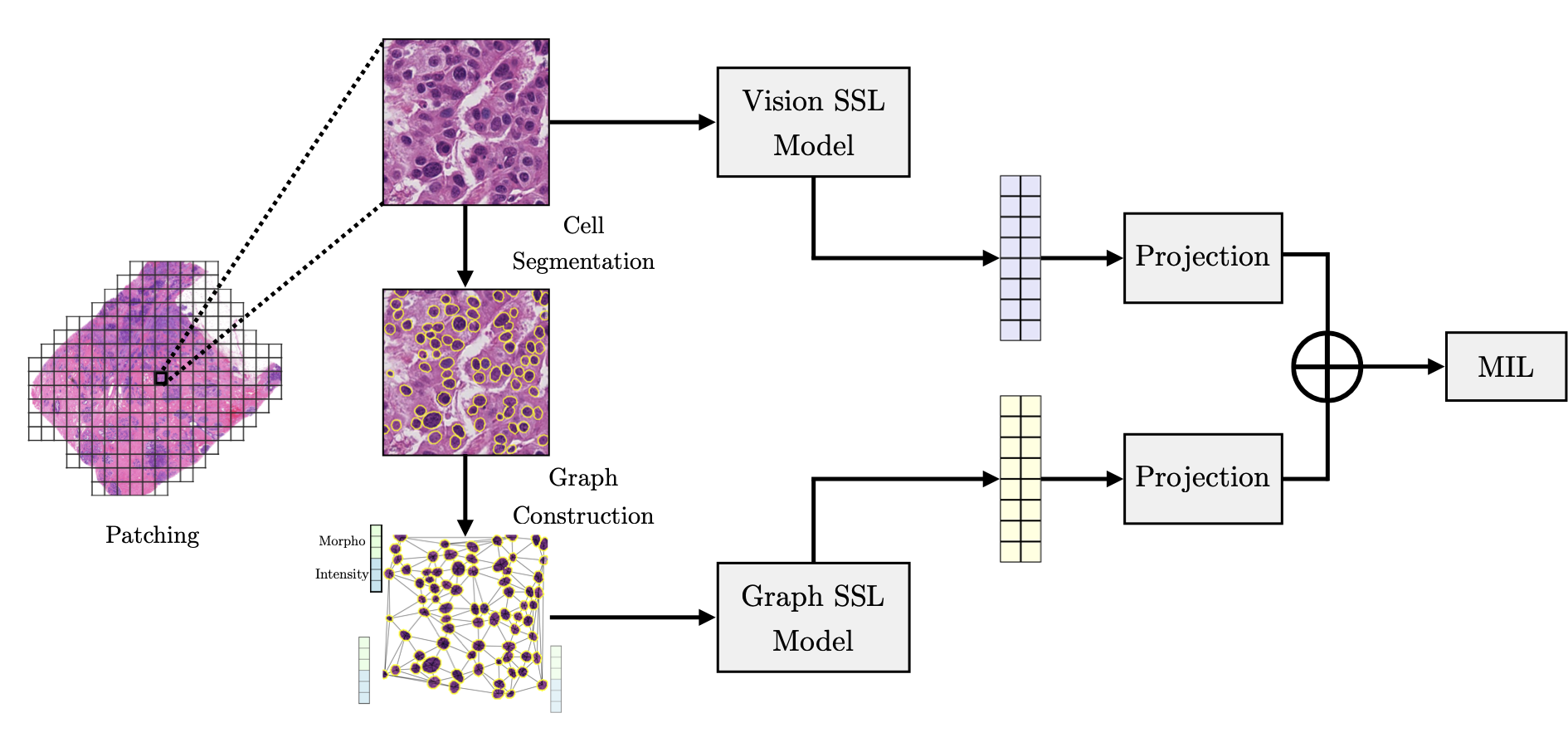
This paper demonstrates that graph-based self-supervision captures spatial structure in digital pathology patches and achieves similar performance to vision-based models using 12x fewer parameters. It also shows late multi-modal fusion of images and graphs improves upon single-modal baselines in digital pathology.

This study presents a unified benchmarking framework that evaluates MIL algorithms at both bag and instance levels, quantifying performance, learnability, and interpretability. Experiments on synthetic and digital pathology datasets reveal that although bag-level performance is robust across aggregation strategies, instance-level metrics are significantly affected by sample size and feature noise.

This analysis shows that graph structure is learned in the initial convolutional layers, typically before any pooling schemes are applied, by perturbing the input graph structure at varying depths of the hierarchical graph neural network. In fact, many popular benchmarking datasets for graph-level tasks only exhibit limited structural information relevant to the prediction task, with structure-agnostic baselines often matching or outperforming more complex GNNs. These findings shed light on the empirical underperformance of graph pooling schemes and motivate the need for more structure-sensitive benchmarks and evaluation frameworks.
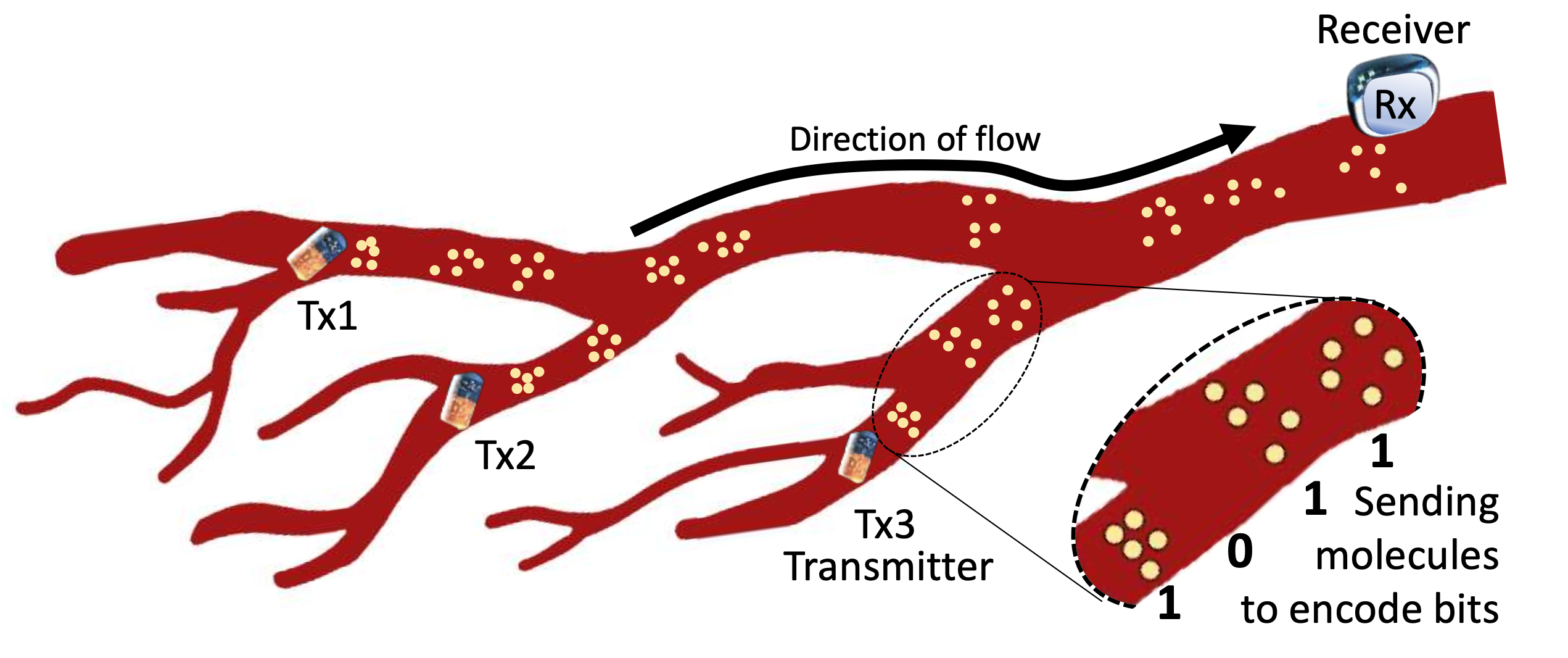
This work introduces MoMA, a molecular multiple access protocol that enables communication between multiple transmitters and a receiver in molecular networks. It addresses key challenges in molecular communication, such as lack of synchronization and high inter-symbol interference, and scales up to four transmitters in the synthetic testbed evaluation.
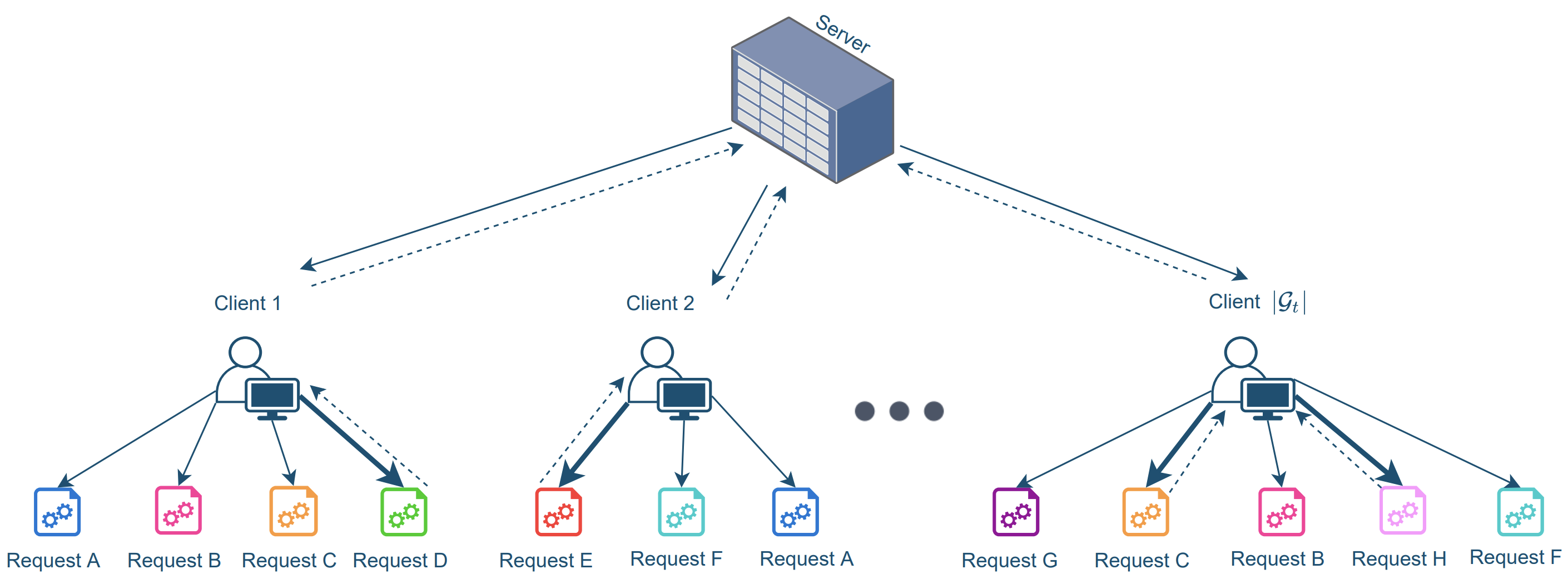
This paper proposes TCGP-UCB which is an algorithm for combinatorial contextual bandit problems with privacy-driven group constraints. It balances between maximizing cumulative super arm reward and satisfying group reward constraints and can be tuned to prefer one over the other, with information-theoretic regret bounds.
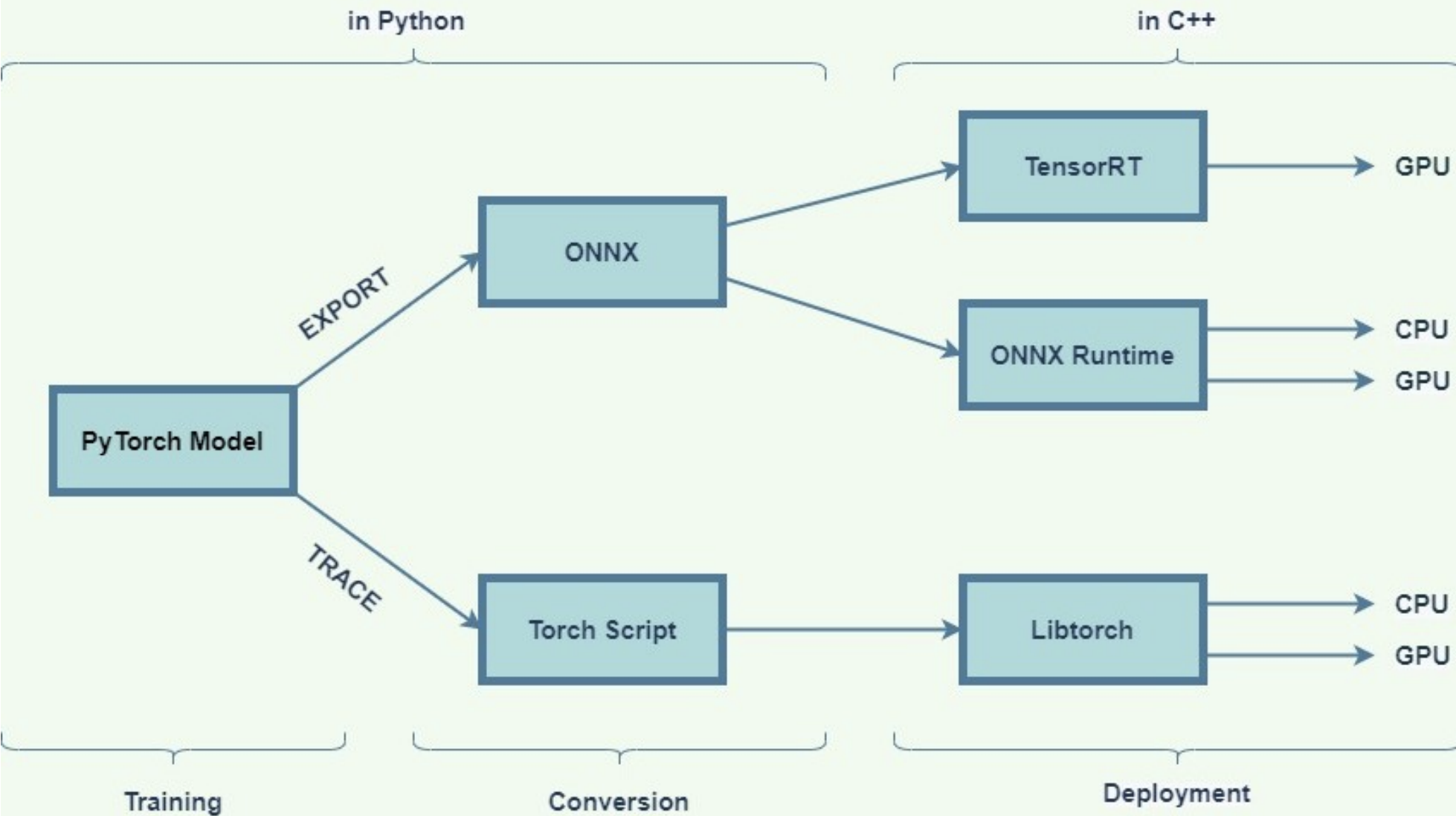
This study benchmarks inference latency across multiple machine learning frameworks using a 2-layer neural network model. The model is implemented in PyTorch and converted to TorchScript and ONNX formats. Inference is performed using LibTorch, ONNX Runtime, and TensorRT on both CPU and GPU. Results show that TensorRT with ONNX delivers the fastest performance, demonstrating its efficiency and potential for deployment scenarios.